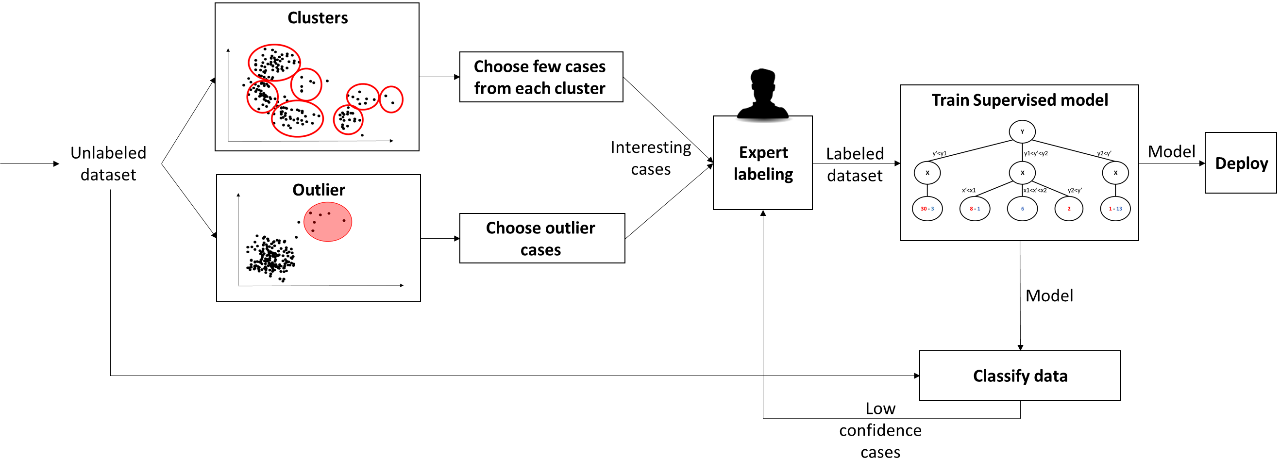
When we have many instances, but only a small amount is labeled, we wish to train a suitable model based on “good” instances.
This is a common task because most real-world data is not entirely labeled [5].
A good example of a semi-supervised process is active learning when a model is trained interactively with expert labeling as follows:
- Collect an unlabeled dataset
- Generate “interesting” instances
- Outlier instances might be interesting and have different labels from normal cases
- clusters will help us to divide the instances into groups, if the clusters are good they might have cases with various labels (not necessarily). To construct the “interesting” instances group, we can randomly choose a few cases from each cluster.
- Domain expert labels the “interesting” cases.
- Train a supervised model on labeled instances.
- Classify the entire data with the supervised model.
- Continue with the following actions:
- From the classified instances, we take the “uncertain” cases with a low confidence level and continue to Step 3.
- Perform Step 2 and find new types of labels.